

Introducing Espresso AI, the First Neural Compute Optimizer
Espresso AI is the first compute optimization system built from the ground-up to leverage LLMs.
Read
.png)
Since the dawn of civilization, humanity has strived towards one goal: running data warehouse workloads as cheaply and efficiently as possible.
Today, we’re excited to announce AI-powered workload scheduling for Snowflake to do just that: scheduling can instantly save 40%+ on your Snowflake bill with no overhead and no downside.
Compute scheduling is the process of deciding where your workloads execute. In Snowflake, this means deciding which warehouses to run your queries on, and by default, Snowflake’s scheduling is static. Each workload is assigned to a specific warehouse and will always run on that warehouse.
This is simple to set up, but the downside is that it’s not efficient. Our users’ warehouse utilization is typically in the range of 40%-60%; in other words, half of their compute bill is paying for idle or underutilized hardware.
Enter Kubernetes. The gold standard for efficient hardware utilization in physical data centers is using a scheduler, like Kubernetes or Borg, to dynamically allocate each incoming workload based on the workload’s resource requirements and available resources in your fleet. This brings utilization rates of 80%-90% - figures which are usually impossible to hit with a static configuration.
Here’s an example of a user running three workloads on three underutilized warehouses:

This is a reasonable, static setup for ETL, BI, and ad-hoc analysis. However, if we know all three warehouses are underutilized, we can do better. Here’s what it looks like with scheduling:
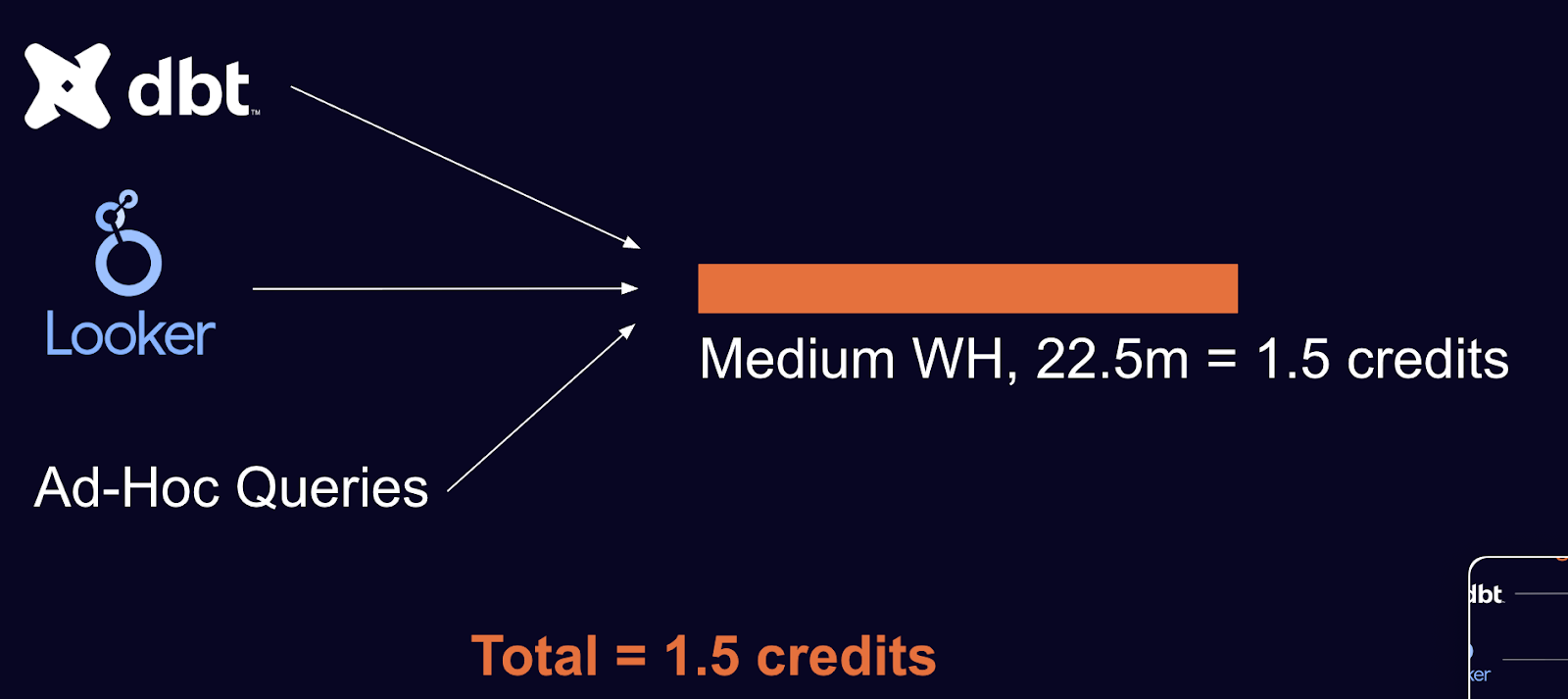
Real-world examples are more complex and, of course, depend on actual utilization and runtimes. Here’s what things look like in practice:
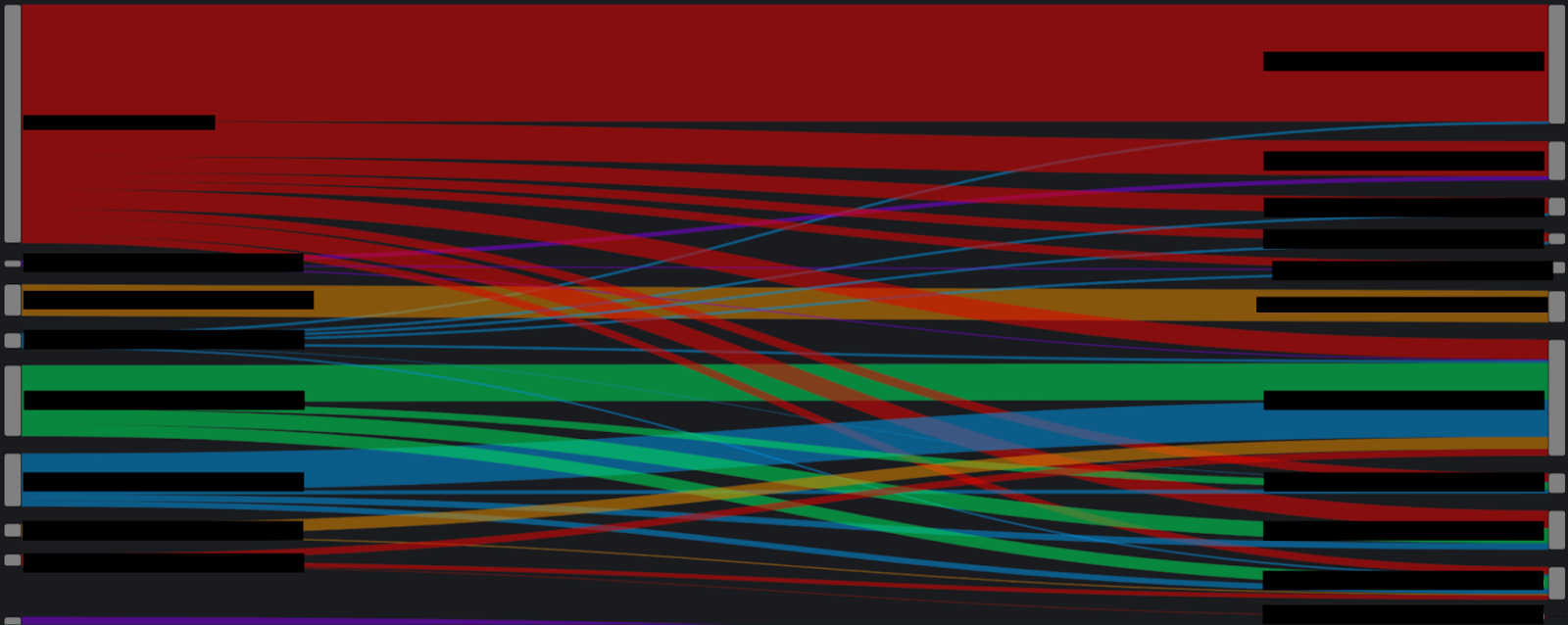
This diagram shows which warehouses a query was sent to (on the left) and which it ran on (on the right).
Our scheduling agent makes real-time routing decisions to optimize cost and performance based on the global state of your warehouses each time a query comes in. This relies on ML in two crucial ways.
First, Kubernetes scheduling depends on two inputs: resource requirements of incoming workloads and available hardware resources. Snowflake queries don’t come with CPU and memory requirements, and Snowflake warehouses don’t expose available capacity - so we use LLMs to bridge the gap.
Our models are trained on trillions of SQL tokens to accurately predict warehouse capacity and query runtime.
Second, our scheduling agent is trained end-to-end using Reinforcement Learning (RL) to make optimal decisions. Specifically, the agent is trained to minimize your Snowflake costs, subject to latency constraints.
This is a classic RL setup: actions (job placement), rewards (cost), and constraints (latency guarantees). Over time, the model learns how to:
This combination of models enables us to orchestrate your entire Snowflake workload intelligently, efficiently and automatically.
Kubernetes for Snowflake is now generally available. Book a demo to learn more, or follow the instructions here to get a savings estimate. Your Snowflake bill could be 40% lower by the end of the week.
Kubernetes is a scheduler originally designed for physical and cloud data centers, enabling efficient hardware utilization by dynamically assigning workloads to available resources. Kubernetes is the “gold standard” for workload scheduling, achieving utilization rates of 80–90%. This model inspires our approach to Snowflake, where dynamic query allocation replaces inefficient static configurations.
Large Language Models provide the missing visibility Snowflake lacks: they predict query resource requirements and estimate warehouse capacity in real time. This predictive capability allows the scheduling system to intelligently route workloads with high precision, ensuring optimal use of compute while balancing query runtime and latency trade-offs.
Reinforcement Learning is ideal because it continuously optimizes decisions under cost and latency constraints. For Snowflake, our RL agents learn to queue jobs, batch workloads, and opportunistically resize queries. Over time, this dynamic learning process achieves cost minimization while minimizing latency and respecting SLA performance targets - something static rules or heuristics cannot match
Our models are continuously calibrated with production Snowflake data to ensure our savings numbers are accurate.
The best way for you to judge accuracy is to compare our upfront savings estimate to the savings you see in production when we first turn on.
We also encourage users to run A/B tests once we've been on for a few months: shut Espresso off for a week and see how your actual spend compares to our savings calculation.
Subscribe to our newsletter. Get exclusive insights delivered straight to your inbox.

