

A Script to Find and Delete Unused Snowflake Tables without Enterprise Access History
Snowflake standard users: run this script to see if you're burning money on unused storage..
Read

We’ve gotten a lot of questions about Snowflake’s Adaptive Compute Warehouses over the past year, in part because of the similarity to our scheduler product (which dynamically routes workloads between your warehouses to deliver cost savings). Adaptive Warehouses is now in public preview, so we ran some benchmarks.
To cut to the chase: this is a premium product focused on performance. That means the bad news is they generally won't save you money - but the good news is that they're often faster than regular warehouses at a given warehouse size, and deliver best-in-class price/performance with lots of concurrent load.
In many ways this is the opposite of Espresso AI's product: we drive down costs as much as possible while matching your current performance. On the other hand, Adaptive Warehouses focuses on delivering exceptional performance, not the most efficient execution. (And, of course, as our models learn how these warehouses work we will begin to use them to power the best price/performance tradeoff you can get on Snowflake.)
Finally, as a disclaimer: we expect these benchmarks to be directionally correct, but you should always test on your own workloads before rolling out production changes.
The actual mechanics and benchmarks here are a bit tricky, so let's start with a summary of how Adaptive Warehouses is meant to work: you define some set of virtual warehouses as ADAPTIVE, with the same t-shirt sizes (XSMALL, SMALL, MEDIUM, etc.), but with a new QUERY_THROUGHPUT_MULTIPLIER (QTM) setting that acts something like a max_cluster setting. QTM controls how many instances to scale to, and then Snowflake will mix queries from all your adaptive warehouses into a compute pool where they figure out how much compute your queries actually need (up to the warehouse size you selected) and then execute your queries on this pool in some (largely unspecified) way. The QTM setting controls the max amount of compute allocated to all the queries assigned to a given adaptive warehouse.
The billing for these is also different. You get billed per-query, rather than per warehouse second with minimum 60s billing. (We were very excited about this, but it's ultimately a mirage - as far as we can tell there's still some sort of billing minimum.)
To start, let's see how it does with TPC-H at various warehouse sizes and the default QTM=2 setting.

The performance is good, but we’re paying for it. It’s not clear we would be better off using Adaptive rather than regular warehouses.
But this benchmark has a wrinkle: it runs the queries from TPC-H sequentially. What if we run these queries in parallel?

That looks a lot better. Adaptive Warehouses are delivering the best performance in a way that scaling warehouse size cannot match, but at significant cost over more efficient baselines. It’s an improvement to the pareto frontier, but only if you were already trying to maximize performance rather than price.
It’s worth keeping in mind that this is a benchmark that Snowflake ships and definitely tuned on, but it gives us a directional idea of what conditions Adaptive Warehouses excel in.
What about fragmented workloads? Espresso is extremely effective here - for example, we often cut costs by routing multi-warehouse workloads to a single cluster. With per-query billing and a compute pool, we expected this to be a native, drop-in replacement for our scheduling product; but that's not what happened.
Specifically, we ran some benchmarks of a trivial scenario where Espresso would cut your bill in half: running two queries on two different warehouses when you only need one. It turns out Adaptive Warehouses still has some sort of minimum billing on these warehouses.
We ran four simple queries on the same xsmall warehouses vs. 4 different xsmall warehouses at 0/15/30/45 second intervals for all of adaptive, gen1, gen2 and Espresso variants, then looked at the metering history on these warehouses:
.svg)
The situation here is a bit noisy on the Adaptive Warehouse runs, but it's more expensive to run sparse workloads on Adaptive Warehouses rather than standard warehouses. Adaptive is not collapsing these queries onto the same warehouse as you would expect. Sometimes we also get some noise with the cheaper variant just being more expensive than expected.
This data also seems to refute the idea that the cost is related directly to sum(QTM per wh) since increasing the QTM on one warehouse does not increase the cost in this sparse scenario.
(It also shows how Espresso can help you reduce fragmentation while maintaining SLAs and chargeback accounting.)
Thinking through these benchmarks around load and what we knew about Snowflake’s sharp edges, we decided to stress test these warehouses under severe load rather than light load.
We ran some benchmarks where we sent 100x queries that take ~8s on a Medium immediately to a warehouse with no ramp up:

The most interesting thing here is that you get basically instantaneous scaling. In a naive QTM=0 (i.e. infinite) setting, you’re definitely going to pay for it, but if you want to respond to large spikes this blows other simple solutions out of the water.
From a pure throughput perspective, this is 50-100% more expensive than a typical non-pathological alternative, but with exceptional performance.
You can get performance that's almost as good for a lot less if you know exactly how much capacity you need:
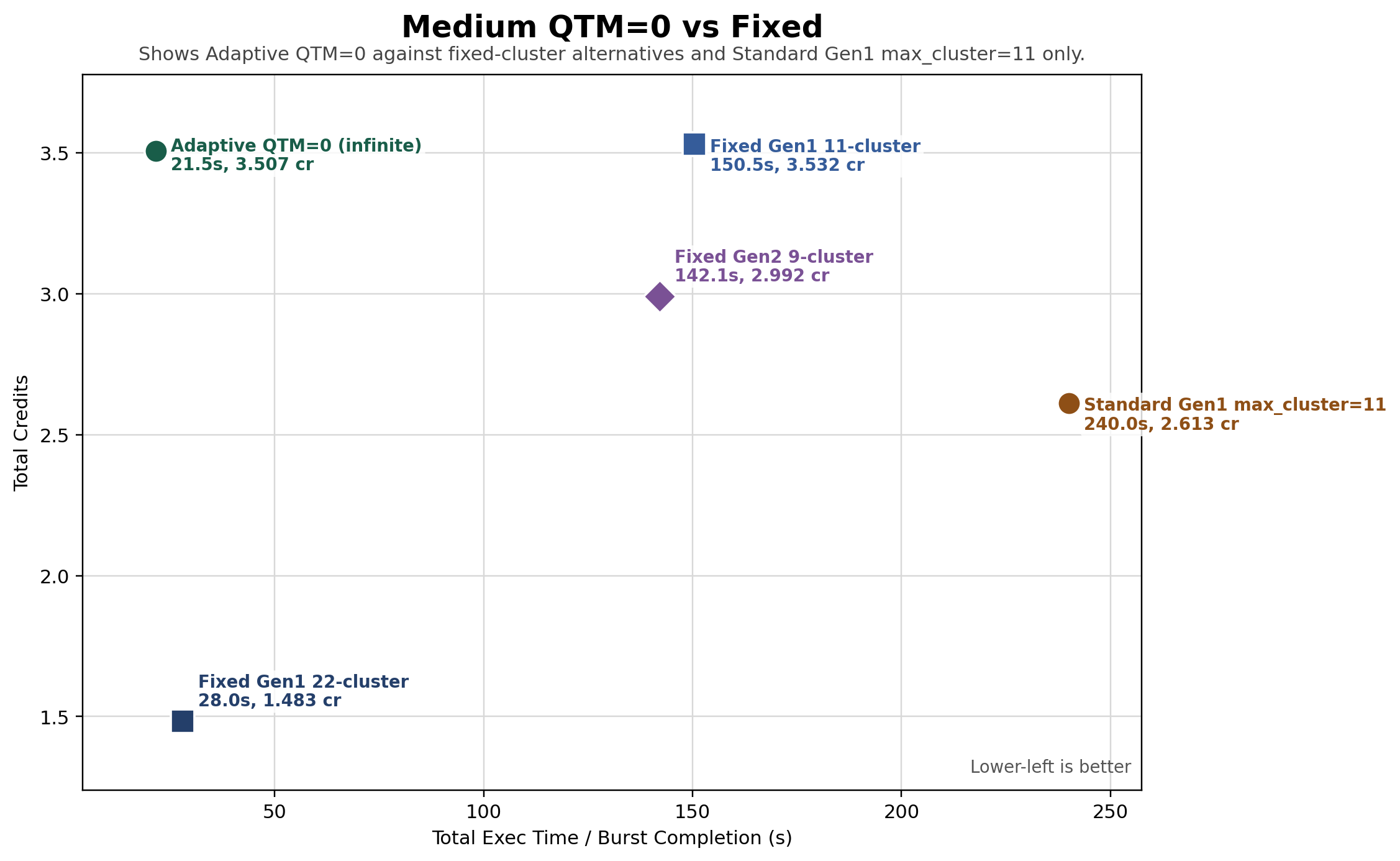
We ran a variety of configs with an optimized min_cluster_ count setting and got 30% slower performance at 40% of the price. That said, it's quite unusual to know exactly how many clusters you need, and if your traffic changes you have a real risk of either overpaying or underprovisioning.
(Some of the outliers on this chart don't make much sense, but we did validate that the results are consistent over multiple runs.)
We also learned that QTM is an important setting:
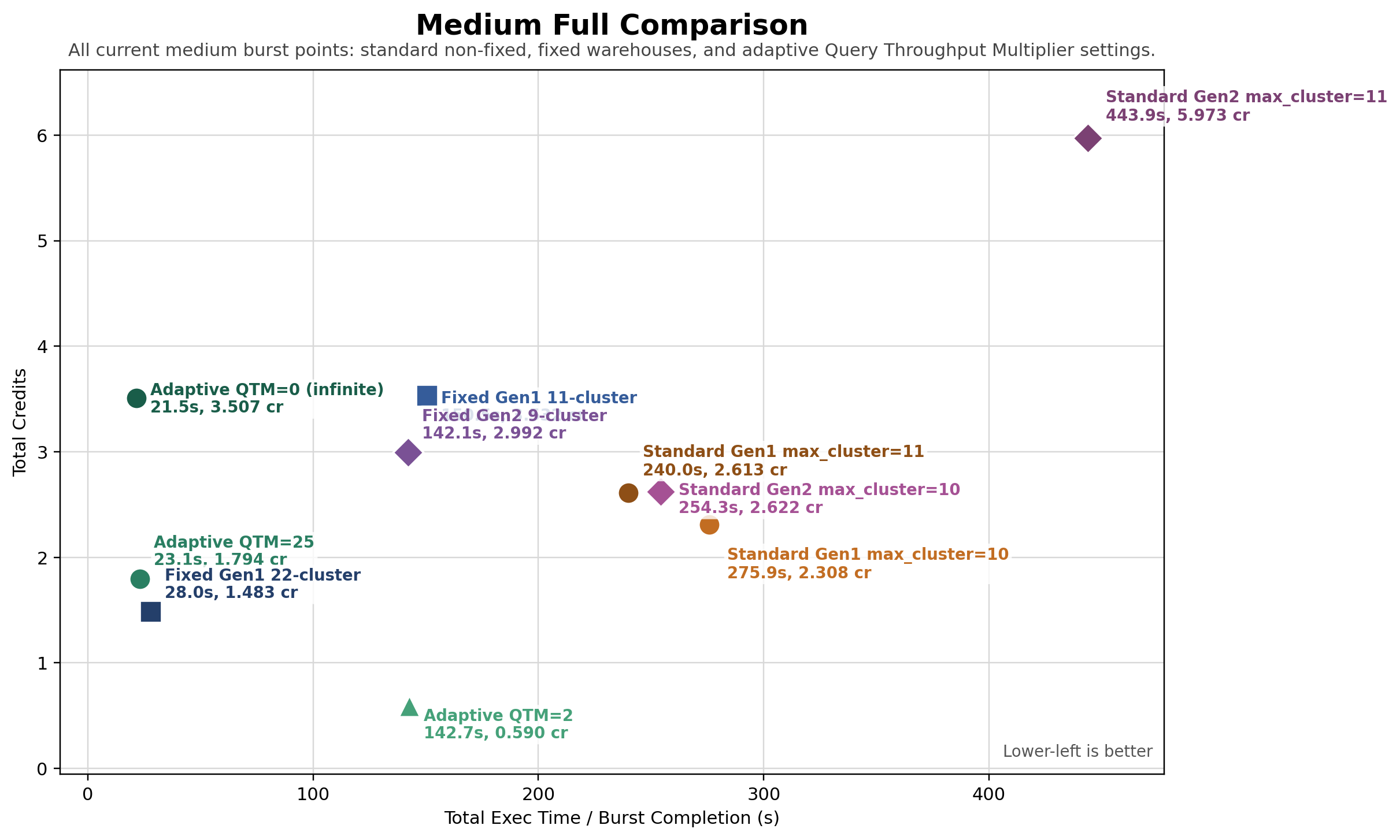
If you know roughly how much traffic you're expecting or want to handle burst loads with minimal queueing, this can be a big lever to reduce the costs from the naive setting; adaptive with QTM=25 has less downside risk than configuring a min_cluster_count of 22. The price, of course, is having another setting to tune, as well as no longer having the instantaneous infinite scalability that QTM=0 provides. In an odd twist, we’ve also seen too-large QTM numbers cost more than QTM=0.
We re-ran this benchmark of 100x ~8s on xsmall warehouses and got similar results. We also did a sweep of various QTM settings, which shows an interesting non-linear relationship:

So far, we've found that the best use of Adaptive Warehouses is near-instantaneous response to bursty traffic - if you have variable workloads there's just no other way to hit the performance this feature offers with Snowflake (but you're going to pay for it). If this is a use-case you’re excited about, you can try it in public preview.
(If you want to let us worry about benchmarking and tuning and save up to 70% on Snowflake with the press of a button, please get in touch at ben@espresso.ai. We'll help you get the best possible price/performance.)
Snowflake Adaptive Warehouses are a public-preview type of virtual warehouse declared with the ADAPTIVE keyword. Instead of running queries on a single dedicated cluster, Snowflake mixes queries from multiple adaptive warehouses into a shared compute pool and dynamically scales compute up to a limit set by the QUERY_THROUGHPUT_MULTIPLIER. Billing is per-query rather than per warehouse-second. They deliver exceptional performance under heavy concurrent or bursty load, but they are a premium, performance-focused product — in these benchmarks they generally do not save money versus well-tuned standard warehouses.
QUERY_THROUGHPUT_MULTIPLIER, or QTM, is a setting on a Snowflake Adaptive Warehouse that acts something like a max_cluster limit. It controls the maximum amount of compute the adaptive warehouse can scale to for the queries assigned to it, up to the configured t-shirt size. QTM=0 gives near-instantaneous, effectively infinite scaling — powerful for burst loads but expensive. A tuned value such as QTM=25 caps downside cost risk while still absorbing spikes, at the price of another setting to tune and the loss of QTM=0's instantaneous scalability.
A virtual warehouse is a Snowflake compute cluster sized with a t-shirt size (XSMALL, SMALL, MEDIUM, etc.) that executes your queries. A standard virtual warehouse runs queries on the cluster you provisioned, with per warehouse-second billing and a 60-second minimum. An Adaptive Warehouse is declared with the ADAPTIVE keyword, shares a compute pool with other adaptive warehouses, scales dynamically up to the QTM ceiling, and uses per-query billing. Regular virtual warehouses are typically cheaper; adaptive is faster under burst load.
On Snowflake, Adaptive Warehouses improve the pareto frontier for performance: you can hit response times that scaling a standard virtual warehouse simply cannot match, especially on bursty workloads. The tradeoff is cost — Adaptive Warehouses ran roughly 50–100% more expensive than non-pathological alternatives in these tests, and they did not collapse sparse multi-warehouse workloads the way a dedicated scheduler would. Adaptive is the right choice when performance matters more than cost; for cost savings, standard warehouses or workload-aware scheduling still win.
Subscribe to our newsletter. Get exclusive insights delivered straight to your inbox.

